最近折腾esp32,想要在自己的小站上安装Arduino-cli环境,根据【此教程】一步步安装下来
但是发现安装esp32的库下载得巨慢
于是研究了一下下载原理
https://raw.githubusercontent.com/espressif/arduino-esp32/gh-pages/package_esp32_index.json
我们平时的步骤是把上面的链接丢进配置文件的additional_urls里,然后运行这行命令来安装esp的库
arduino-cli core install esp32:esp32但是这样在没有魔法的情况下下载得会很慢
其实他要下载的东西就是json里的库包和工具包,也就是下图的platforms和tools
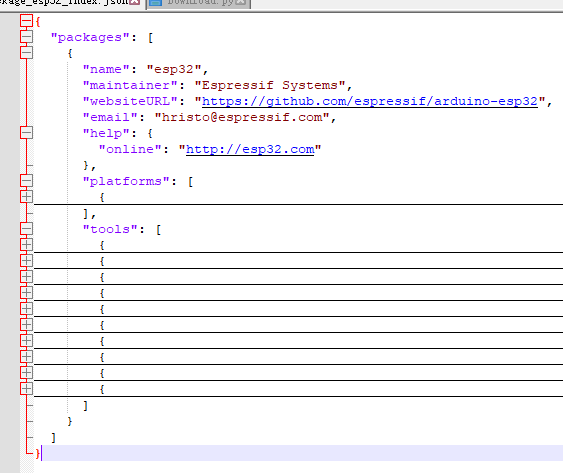
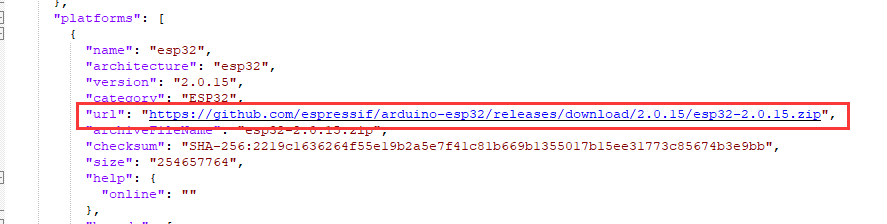

platforms直接下载里面的url就行,tools下的每项都有不同架构的包,下载对应系统架构的包即可
知道要下载的东西后,就可以把这个json下载下来,然后再用python解析下载了,下完了再全部放到安装目录的.arduino15/staging/packages下
我的下载的python脚本如下,使用的话要把json放到py文件的同目录,并调整下载目录和架构即可
import json
import requests
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urlparse
import os
import threading
from tqdm import tqdm
import time
download_dir = "Download"
json_dir = "package_esp32_index.json"
arrch = "x86_64-pc-linux-gnu"
proxy = {
"http": "http://127.0.0.1:7890",
"https": "http://127.0.0.1:7890"
}
# 定义下载函数
def download_file(url, filename, proxy=None):
try:
start_time = time.time()
response = requests.get(url, proxies=proxy, stream=True)
total_size = int(response.headers.get('content-length', 0))
with open(filename, 'wb') as f, tqdm(
desc=filename,
total=total_size,
unit='B',
unit_scale=True,
unit_divisor=1024,
) as pbar:
for data in response.iter_content(chunk_size=1024):
f.write(data)
pbar.update(len(data))
end_time = time.time()
download_time = end_time - start_time
download_speed = total_size / download_time if download_time > 0 else 0
print(f"{filename} 下载完成,用时: {download_time:.2f}秒,平均速度: {download_speed:.2f}B/s")
except Exception as e:
print(f"下载 {filename} 时出现异常: {e}")
urls = []
sizes = []
with open(json_dir, 'r') as f:
data = json.load(f)
urls.append(data["packages"][0]["platforms"][0]["url"])
sizes.append(data["packages"][0]["platforms"][0]["size"])
for tool in data["packages"][0]["tools"]:
for system in tool["systems"]:
if system["host"] == arrch:
urls.append(system["url"])
sizes.append(system["size"])
os.makedirs("Download", exist_ok=True)
# 创建线程并启动下载
threads = []
for index, url in enumerate(urls):
file_path = f"{download_dir}/{os.path.basename(url)}"
if os.path.exists(file_path) and os.stat(file_path).st_size == int(sizes[index]):
print(f"{file_path} exist, skip")
continue
filename = os.path.join(download_dir, os.path.basename(url))
thread = threading.Thread(target=download_file, args=(url, filename, proxy))
thread.start()
threads.append(thread)
# 等待所有线程完成
for thread in threads:
thread.join()
print("所有文件下载完成")